Citation
Arghya Chatterjee (CSMD, ORNL), Gonzalo Alvarez (CCMS, ORNL), Eduardo F. D'Azevedo (CSMD, ORNL), Wael R. Elwasif (CSMD, ORNL), Oscar Hernandez (CSMD, ORNL), and Vivek Sarkar (GA Tech)
Abstract
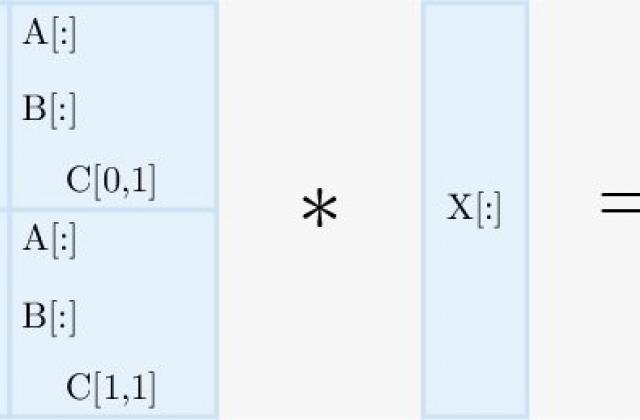
With the rapidly changing microprocessor designs and architectural diversity (multi-cores, many-cores, accelerators) for the next generation HPC systems , scientific applications must adapt to the hardware, to exploit the different types of parallelism and resources available in the architecture. To get the benefit of all the in-node hardware threads, it is important to use a single programming model to map and coordinate the available work to the different heterogeneous execution units in the node (e.g., multi-core hardware threads (latency optimized), accelerators (bandwidth optimized), etc.). Our goal is to show that we can manage the node complexity of these systems by using OpenMP for in-node parallelization by exploiting different "programming styles" supported by OpenMP 4.5 to program CPU cores and accelerators. Finding out the suitable programming-style (e.g., SPMD style, multi-level tasks, accelerator programming, nested parallelism, or a combination of these) using the latest features of OpenMP to maximize performance and achieve performance portability across heterogeneous and homogeneous systems is still an open research problem. We developed a mini-application, Kronecker Product (KP), from the original DMRG++ application (sparse matrix algebra) computational motif to experiment with different OpenMP programming styles on an OpenPOWER architecture and present their results in this paper.
Read PublicationLast Updated: May 28, 2020 - 4:06 pm