Achievement
In Monte Carlo neutron transport simulations, a computational routine commonly known as “cross-section lookup” has been identified as being the most computationally expensive part of these applications. Unfortunately, the algorithms commonly used in the cross-section lookup routine were originally devised and developed for CPU-based platforms and have seen limited study on GPUs to date. Additionally, existing cross-section lookup implementations such as XSBench apply approximations which may have a negligible effect on CPUs but may be quite impactful to performance on GPUs given the more resource-limited nature of the latter. As a result, we have created VEXS, a new tool for modeling the cross-section lookup routine which removes or at least reduces the approximations made by XSBench in order to provide a more realistic prediction of algorithm performance on GPUs.
Significance and Impact
Monte Carlo neutron transport simulations are a powerful simulation method used often in the field of nuclear engineering to analyze scenarios of interest, such as reactor core design and radiation dose calculations. These codes have gained a reputation of being mostly “embarrassingly parallel”, however a specific routine which is common to all neutron transport simulations, the cross-section lookup routine, has been identified as composing a significant fraction of problem runtime. This routine has been found to be generally memory-bound, and often latency-bound in particular. Several algorithms have been developed to reduce the time-to-solution for these routines. These algorithms have had great success reducing computation time on their original architectures, CPUs, however they have not seen as significant study or even implementation on GPUs. VEXS (Very Easy XS) is a new tool for modeling the cross-section lookup routine on GPUs, which removes or reduces approximations existing in CPU-based implementations in order to bring performance prediction closer to those available from real-world production codes.
Research Details
- A detailed description and analysis of the computational scenario that XSBench and VEXS seek to emulate, as well as an analysis of the reference code Shift.
- Introduction to implementation details of the XSBench and VEXS applications, and explanation of the motive behind removing certain approximations.
- Detailing of the algorithms of interest expressed in all three codes, as well as an initial analysis of potential algorithm behavior.
- Comparison of performance results from XSBench and VEXS vs. Shift.
- Comparison of profiling results from XSBench and VEXS vs. Shift.
Citation and DOI:
Forrest Shriver, Seyong Lee, Steven Hamilton, Justin Watson and Jeffrey Vetter, Enhancing Monte Carlo proxy applications on GPUs, 10th IEEE International Workshop on Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS19), in conjunction with SC19, 2019.
Overview
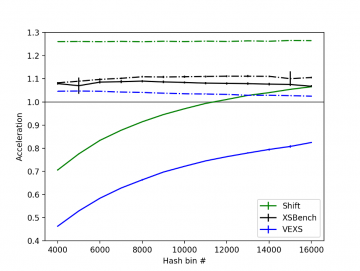
Shown in Figure 1 is a comparison between Shift unit tests, XSBench, and VEXS for a fresh scenario on a P100 GPU. XSBench appears to predict that the hash-accelerated binary search and hash-accelerated linear search will be very close to each other in terms of performance and appear to be very agnostic to the number of hash bins used in the calculation. This is in direct contrast to the Shift unit tests, which indicate that there will be a significant performance difference between the two implementations and that the hash-accelerated linear search seems to show a heavy dependence on the number of hash bins used. By comparison, VEXS correctly captures the hash bin-sensitive behavior for the hash-accelerated binary search, the hash bin dependency shown in the reference for the hash-accelerated linear search, and the performance degradation at lower numbers of hash bins.
Last Updated: April 6, 2021 - 12:23 pm