Achievement
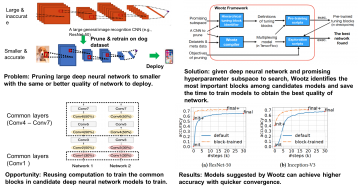
Wootz framework accelerates Convolutional Neural Network (CNN) pruning process via reusing computation to train candidate training models on top of the composability hypothesis on neural network design. Our evaluation results on ResNet-50 and Inception-V3 shortens the neural network pruning process by up to 186.7xand 30.2x, respectively. The trained models through this approach is up to 70% more compact, while achieving the same or better quality of prediction.
Significance and Impact
Convolutional Neural Networks (CNN) are widely used for deep learning tasks. CNN pruning is an important method to adapt a large CNN model trained on general datasets to fit a more specialized task or a smaller device. The key challenge is on deciding which filters to remove in order to maximize the quality of the pruned networks while satisfying the constraints. It is time-consuming due to the enormous configuration space and the slowness of CNN training.
The long exploration time of CNN pruning has been a major barrier for timely delivery of many AI products. Wootsdramatically shortens the exploration time of CNN pruning, allowing agile deploy deep learning models to the target systems.
Research Details
We model the process of training deep neural networks after compiling program source codes to generate binary files. We design a hierarchical compression-based algorithm, on top of a traditional compiler technique. This compiler technique constructs a directed acyclic graph from the description of candidate deep neural networks to be trained. The directed acyclic graph informs the most important tuning blocks to pre-train in order for us to re-use computation for training models.
This work is published in Proceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 2019.
Last Updated: January 15, 2021 - 11:40 am