Achievement
Developed and evaluated a Markov-chain based I/O request predictor and a minimum-cost maximum-flow algorithm that incorporates runtime load measurements for selecting Lustre storage targets, which can improve load balance and storage bandwidth versus standard Lustre round-robin selection.
Significance and Impact
This work demonstrates that runtime storage I/O resource monitoring can successfully be used along with dynamic, learning-based prediction of I/O behaviors to improve load balance and performance for concurrent data-intensive applications using high performance distributed storage systems such as Lustre.
Research Details
- Developed a Markov-chain model to predict I/O requests based on prior application behavior
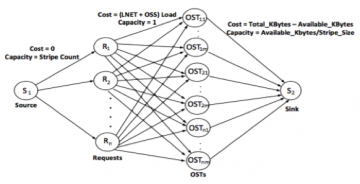
- Designed a flow network model of Lustre I/O including client requests, network routers (LNET), object storage servers (OSS), and object storage targets (OST) that incorporates current load information
- Developed a minimum-cost maximum flow (MCMF) algorithm based on the Ford-Fulkerson method to balance assignment of client requests to OSTs
- Verified effectiveness of load balancing approach using a simulation environment with up to 3,600 OSTs, and a live cluster running Lustre 2.8
Overview
High performance computing (HPC) applications are increasingly data-intensive, driven by increases in simulation fidelity and big data analytics approaches. Current HPC storage systems, such as the Lustre parallel file system, exhibit resource contention and decreased performance due to uneven load distribution across storage resources when servicing concurrent data-intensive applications. Our research attempts to improve storage I/O load balancing using runtime monitoring of resource utilization and dynamic methods for storage resource selection. Unlike prior methods, we focus on a global view of the storage system, rather than optimizing I/O for a specific application, and use dynamic methods that adjust to current workloads, rather than static policies. We use machine learning to help predict I/O behaviors for individual applications based on prior requests. Current and predicted requests, along with dynamic information on resource utilization throughout the storage system, are used within a minimum-cost maximum-flow network model to select a load-balanced assignment of requests to storage resources. Our experimental results using a detailed simulator and a live cluster environment show that our approach improves storage load balance versus the default round-robin selection in Lustre 2.8, and has a secondary benefit of increasing overall I/O bandwidth for applications.
Last Updated: May 28, 2020 - 4:04 pm