Achievement
We identify several design considerations that need to be taken care of while developing applications for the new architecture and we evaluate their performance effects on the EMU-chick hardware. We also present a modified BFS algorithm for the EMU system and give experimental results for its execution on the platform
Significance and Impact
EMU presents a different approach to solve increasingly worsening memory bottleneck problem in high performance computing. The proposed solution relies on migrating threads to the location where the memory resides, and EMU achieves this without programmer intervention.
Our work shows that there are several unique architectural considerations that need to be addressed while developing for the EMU platform. While the programming interface mainly relies on Cilk, proper usage of intrinsics are required for performance effective algorithm design.
Overview
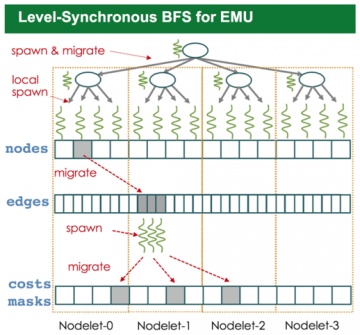
EMU is a novel architecture that provides scalable access to a com- mon partitioned global address space (PGAS) through a simple programming interface. The hardware is hierarchically organized as nodes, nodelets, and gossamer cores from top to bottom, and each nodelet owns a partition of the globally addressable memory. Different from existing PGAS and active messaging-based solutions, a thread in EMU migrates to the memory location of the operand that the current instruction operates on.
In general, reducing memory access times is a primary concern for applications running on traditional SMP based systems. However, on EMU, minimizing total number of thread migrations is the most important design goal. Memory allocation patterns, thread spawning strategies, and parallelism granularity are the three factors that affect the total number of migrations.
EMU shows a scaling curve very close to linear, whereas CPU performance deviates from the linear curve as the number of nodes increases. Also, EMU handles the increase in average degrees better than the CPU execution. Increasing neighbor counts enables better distribution across nodelets hence ends up in larger performance benefits. In CPU execution, on the other hand, since the major bottleneck is memory bandwidth, higher degree graphs do not perform differently.
Last Updated: May 28, 2020 - 4:02 pm