Project Status: Active
Motivation
- Directive-based GPU programming models are gaining momentum since they transparently relieve programmers from dealing with complex language syntax of low-level GPU programming, which often involves diverse architectural details.
- However, too much abstraction in directive models puts a significant burden on programmers in terms of debugging and performance optimizations.
- To improve debuggability/tunability for the directive-based GPU programming models, we must have a systematic approach that exposes more information to programmers while still maintaining high-level abstraction.
- To facilitate research on other important features, such as resilience and scalability, more intuitive and extensible compiler framework will be need.
Open Accelerator Research Compiler (OpenARC)
OpenARC is a new, open source compiler framework, which provides extensible environment, where various performance optimizations, traceability mechanisms, fault tolerance techniques, etc., can be built for better debuggability/performance/resilience on the complex accelerator computing. OpenARC has the following salient features:
- OpenARC is the first open source compiler supporting full features of OpenACC specification v1.0 and subset of v2.0, which allows full research contexts on directive-based GPU computing.
- OpenARC is designed with extensibility in mind. Built on top of the Cetus compiler infrastructure, OpenARC is equipped with various advanced compile-time analysis and transformation techniques, which provide basic building blocks to easily create more advanced compiler passes. Combined with its very high-level intermediate representation (IR) augmented with a rich set of directives, OpenARC provides a powerful research framework for various source-to-source translation and instrumentation experiments, even for porting various Domain-Specific Languages (DSLs).
- Within OpenARC, various traceability mechanisms can be implemented to keep the connection between input directive models and output codes/performance, because OpenARC has clear separation between analysis passes and transformation passes, and all compiler passes communicate with each other through annotations.
- As an OpenACC directive compiler, OpenARC has various additional directives/environment variables for internal tracing and GPU-specific optimizations. Combined with its built-in tuning tools, OpenARC allows users to control overall OpenACC-to-GPU translation and optimization in a fine-grained, but still abstract manner, offering very high tunability.
Extensible Program Representation in OpenARC
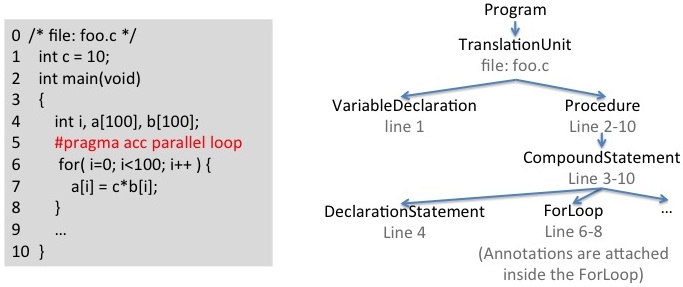
Built on top of the Cetus compiler infrastructure, OpenARC's program representation inherits several of its predecessor's salient features. OpenARC's IR is implemented in the form of a Java class hierarchy, and it provides an Abstract Syntax Tree (AST)-like syntactic view of the input program that makes it easy for compiler-pass writers to analyze and transform the input program. As shown in the above figure, the Program class type represents the entire program that may consist of multiple source files, and the TranslationUnit class type represents each of the source files. Each TranslationUnit object contains IR objects of two base types: Declaration and Statement. Each Declaration object contains Declarator IR objects, and each Statement object consists Expression IR objects. Other IR class types for specific language constructs are derived from these base classes (e.g., DeclarationStatement represents a Statement that contains a Declaration).
This hierarchical IR class structure provides complete data abstraction such that compiler-pass writers need only manipulate the objects through access functions, thus the AST-like view. OpenARC supports the following important features derived from Cetus.
- Traversable IR objects. All OpenARC IR objects extend a base class Traversable, which provides the basic functionality to iterate over IR objects. Combined with various built-in iterators (e.g., BreadthFirst, DepthFirst, Flat, etc.), these provide easy traversal and search over the AST-like, n-ary tree structures of the program representation.
- Rich Annotations. Annotation is a base class type to represent any type of annotations used in OpenARC. By deriving this base class, various types of information, such as comments, directives, raw codes to be inlined, etc., can be added to the OpenARC IRs. An annotation can be associated with any Annotatable IR objects (e.g., OpenMP/OpenACC directives attached to a ForLoop statement) or can be stand-alone like a comment statement.
- Flexible Printing. The printing functions in each IR class type allow flexible rendering of the program representation, depending on the target languages and translation goals.
- Symbol table. OpenARC's symbol table functionality provides information about identifiers and data types by directly accessing the information stored in declaration statements without using separate and redundant symbol table storage.
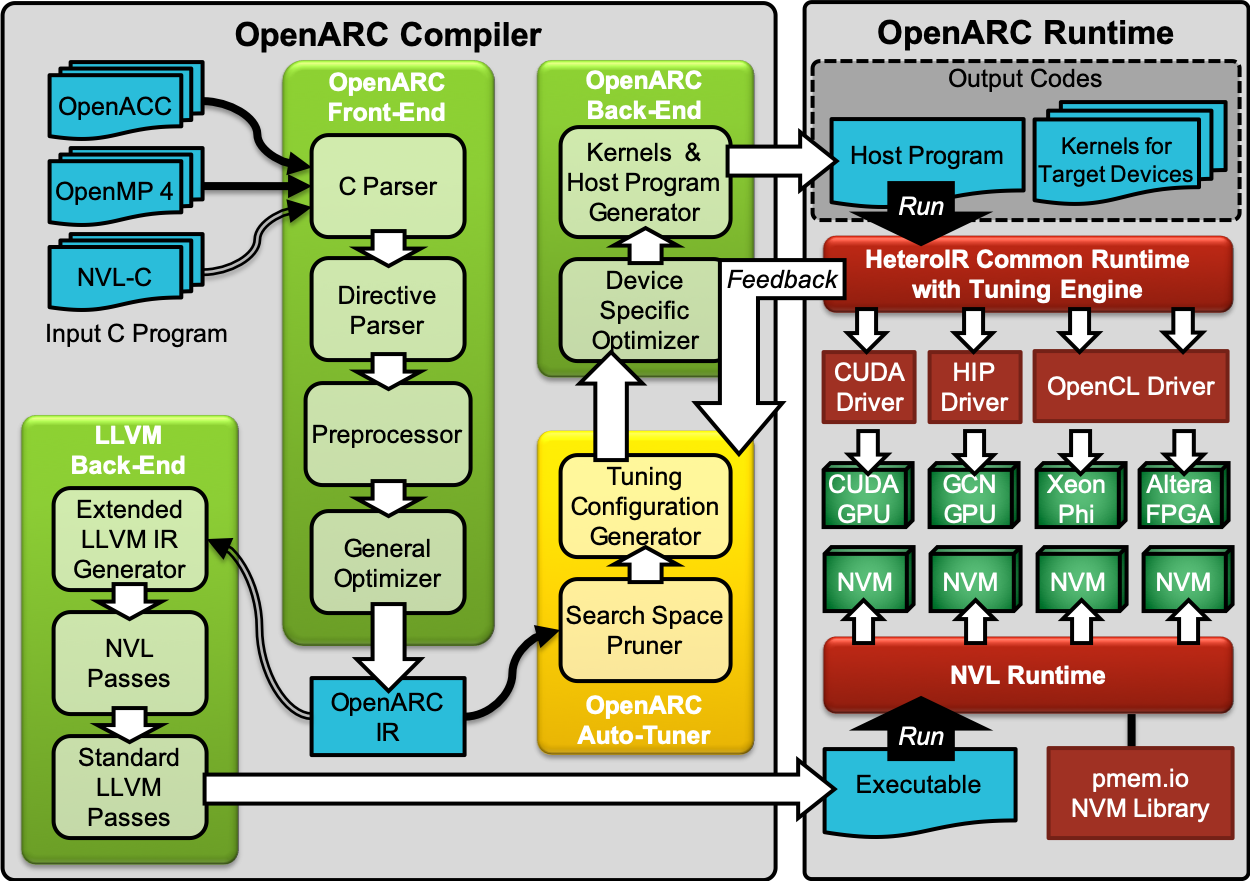
OpenARC Compilation Flow
The OpenARC compiler consists of the following major passes, each of which provides one or more checkpoints. Within checkpoints, intermediate results can be saved as output codes with annotations. This is useful for manual debugging or for implementing traceability mechanisms.
- Cetus parser calls C preprocessor to handle header files, macro expansion, etc., and converts the preprocessed OpenACC program into an internal representation (OpenARC IR).
- Input preprocessor parses OpenACC directives and performs initial code transformations for later passes, including selective procedure cloning to enable context-sensitive, interprocedural analyses/transformations.
- OpenACC loop-directive preprocessor interprets loop directives, extracts necessary implicit information from the loop constructs and stores them as internal/external annotations, and performs initial loop transformations according to explicit/implicit rules.
- OpenACC analysis checks the correctness of the overall OpenACC directives and derives sharing rules for the data not explicitly specified by programmers.
- User-directive handler interprets additional annotations provided as a separate file, and stores them into IR.
- Optimization pass performs various optimizations such as privatization, reduction recognition, locality analysis, etc. All the optimization results are stored as annotations to inform later transformation passes.
- Transformation pass conducts several pre-transformations according to the results passed from the optimization pass.
- OpenACC-to-Accelerator translation generates output accelerator codes with post-transformations that are possible only at output codes.
OpenARC Tuning Framework
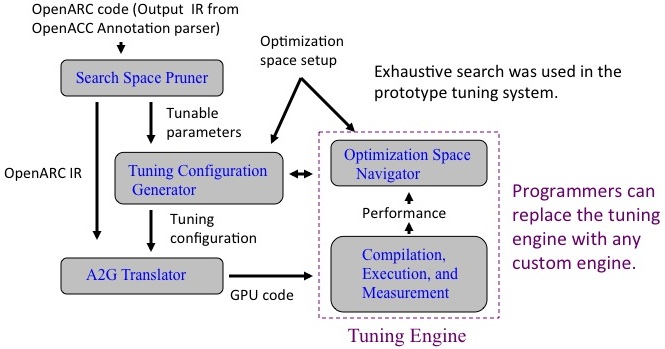
The overall tuning process is as follows:
- The search space pruner analyzes an input OpenARC program plus optional user settings, which exist as annotations in the input program, and suggests application tuning parameters.
- The tuning configuration generator builds a search space, further prunes the space using the optimization space setup file if user-provided and generates tuning configuration files for the given search space.
- For each tuning configuration, the A2G translator generates an output accelerator program.
- The tuning engine produces executables from the generated accelerator programs and measures the performance of the output programs by running the executables.
- The tuning engine decides a direction to the next search and requests to generate new configurations.
- The last three steps are repeated, as needed.
In the example tuning framework, a programmer can replace the tuning engine with any custom engine; all the other steps from finding tunable parameters to complex code changes for each tuning configuration are automatically handled by the compilation system in OpenARC.
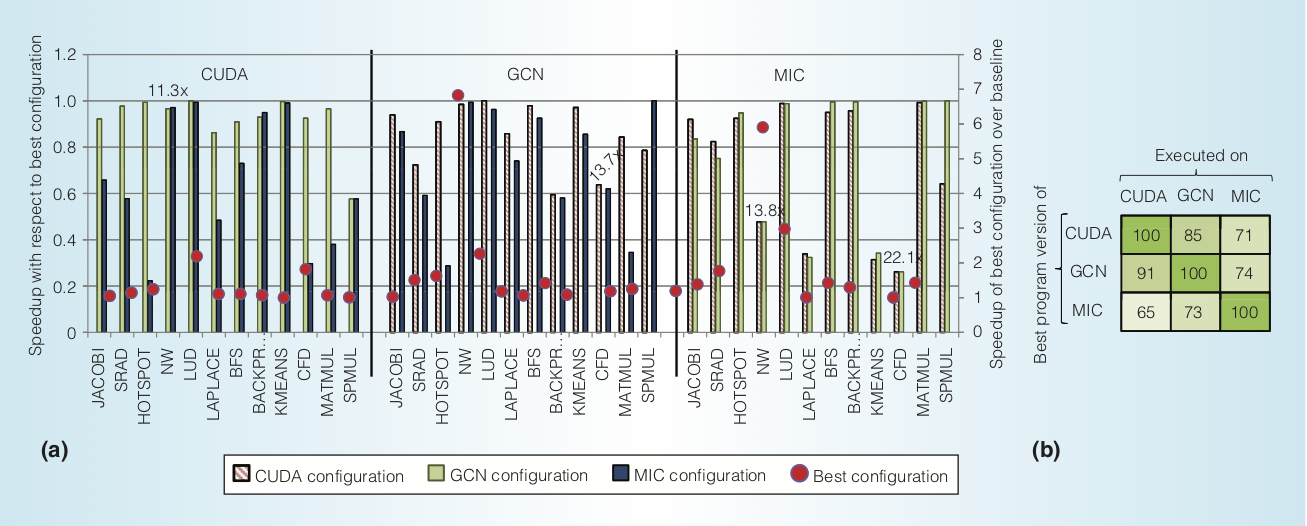
Preliminary Evaluation
The following figure shows the performance portability of OpenACC programs translated by OpenARC, where the effects of different program settings and compiler optimizations on three architectures (GTX 680 for CUDA, Radeon HD 7970 for GCN, and Knights Corner for MIC) were examined using 12 OpenACC programs.
Publications
To cite OpenARC, please use the following papers (you can download bibtex files from each link):
To cite OpenARC-related research, please use the following papers:
Jacob Lambert, Seyong Lee, Jeffrey S. Vetter, and Allen D. Malony, CCAMP: An Integrated Translation and Optimization Framework for OpenACC and OpenMP, SC 2020: The International Conference for High Performance Computing, Networking, Storage, and Analysis, 2020.
Seyong Lee, Jacob Lambert, Jungwon Kim, Jeffrey S. Vetter, and Allen D. Malony, OpenACC to FPGA: A Directive-Based High-Level Programming Framework for High-Performance Reconfigurable Computing, SC 2018: The International Conference for High Performance Computing, Networking, Storage, and Analysis, Poster, 2018
Michael Wolfe, Seyong Lee, Jungwon Kim, Xiaonan Tian, Rengan Xu, Barbara Chapman, Sunita Chandrasekaran, The OpenACC data model: Preliminary study on its major challenges and implementations, Parallel Computing: systems & applications Volume 78, Pages 15-27, October 2018
Jacob B. Lambert, Seyong Lee, Jungwon Kim, Jeffrey S. Vetter, and Allen D. Malony, Directive-based, High-Level Programming and Optimizations for High-Performance Computing with FPGAs, ICS 2018: The 32nd ACM International Conference on Supercomputing, June 2018
Mehmet E. Belviranli, Seyong Lee, Jeffrey S. Vetter, and Laxmi N. Bhuyan, Juggler: A Dependency-Aware Task Based Execution Framework for GPUs, PPoPP18: ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, 2018
Gregory Herschlag, Amanda Randles, Seyong Lee, and Jeffrey S. Vetter, GPU Data Access on Complex Geometries for D3Q19 Lattice Boltzmann Method, IPDPS18: IEEE International Parallel and Distributed Processing Symposium, 2018
Michael Wolfe, Seyong Lee, Jungwon Kim, Xiaonan Tian, Rengan Xu, Sunita Chandrasekaran, and Barbara Chapman, Implementing the OpenACC Data Model, The Seventh International Workshop on Accelerators and Hybrid Exascale Systems (AsHES) in conjunction with IPDPS17, 2017
Joel E. Denny, Seyong Lee, and Jeffrey S. Vetter, Language-Based Optimizations for Persistence on Nonvolatile Main Memory Systems, 31th IEEE International Parallel & Distributed Processing Symposium (IPDPS), 2017
Seyong Lee and Jeffrey S. Vetter, OpenARC: Open Accelerator Research Compiler for Directive-Based, Heterogeneous Computing, GTC14: GPU Technology Conference, Poster, March 2014
Seyong Lee and Jeffrey S. Vetter, Moving Heterogeneous GPU Computing into the Mainstream with Directive-Based, High-Level Programming Models, DOE Exascale Research Conference, Position Paper, April 2012
Software Download
- OpenARC is currently hosted in the ORNL GitLab repository (https://code.ornl.gov/f6l/OpenARC), which requires an ORNL GitLab account to access; please contact us to get an account to access the OpenARC repository.
Related Links
PROTEAS: PROgramming Toolchain for Emerging Architectures and Systems
Cosmic Castle - DARPA Domain Specific Systems on a Chip
RAPIDS2: SciDAC Institute for Computer Science, Data, and Artificial Intelligence
Clacc: OpenACC Support for Clang and LLVM
OpenACC: Directives for Accelerators
NVL-C: Programming NVM as Persistent, High-Performance Main Memory
OpenMPC: Extended OpenMP Programming and Tuning for GPUs
CETUS: A Source-to-Source Compiler Infrastructure
Contact
- Seyong Lee (Email: lees2 AT ornl DOT gov)
Last Updated: February 25, 2021 - 2:51 pm