Achievement
Created an understanding of the impact of reliability, availability and serviceability (RAS) events on scientific application performance. For example, non-fatal RAS events have shown to impact application performance.
Significance and Impact
Improves science productivity with unique and important insights for users, operators, and developers into application performance impacted by different system components
Research Details
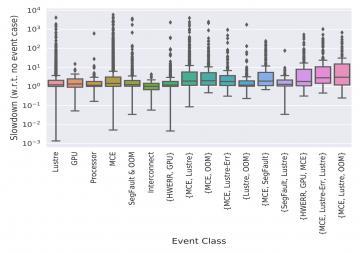
- Co-analyzed 13 months of application scheduling and RAS event data from ORNL’s Titan supercomputer
- Studied the performance characteristics of scientific applications which are most affected by RAS events
- Identified system components that are most likely to impact the performance of scientific applications
- Quantified the slowdown of scientific application jobs due to RAS events from different components
Overview
Reliability, availability, and serviceability (RAS) events are recorded from almost all components in a high-performance computing (HPC) system and therefore provide useful insights into the reliability of the system. The benefit of analyzing such log data is manifold, including for enabling efficient system operation, system users debugging and design, and computer science research.
Although prior studies have analyzed RAS events, they do not correlate RAS mechanisms with application executions and therefore fail to understand the impact of RAS events on application performance. In this work, the co-analysis reveals that RAS events do impact application performance in the majority of the cases. Intuitively, it is found that large-scale and longer duration applications are more likely to be impacted by reliability events causing performance slowdown and variability.
The analysis also reveals that different HPC system components affect application performance differently and the impact can take place irrespective of whether there is an application failure or not. This is an important finding, since it is normally assumed that non-fatal events do not impact application performance, given HPC systems are configured to handle such cases efficiently and have minimal overheads.
A good starting point to increase operational efficiency of HPC systems is by providing meaningful system status information to users upon the completion of their application executions resulting in limited number of application re-runs. Overall, our analysis provides important insights about the characteristics of applications or runtime scenarios which require deployment of resilience mechanisms.
R. A. Ashraf and C. Engelmann. “Analyzing the Impact of System Reliability Events on Applications in the Titan Supercomputer”. In Proceedings of the 31st International Conference on High Performance Computing, Networking, Storage and Analysis (SC) Workshops 2018: 8th Workshop on Fault Tolerance for HPC at eXtreme Scale (FTXS) 2018, Dallas, TX, USA, Nov. 16, 2018.
Last Updated: January 15, 2021 - 4:53 pm