Jeffrey Vetter
Highlights
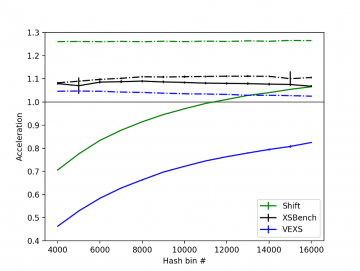
Shown in Figure 1 is a comparison between Shift unit tests, XSBench, and VEXS for a fresh scenario on a P100 GPU. XSBench appears to predict that the hash-accelerated binary search and hash-…
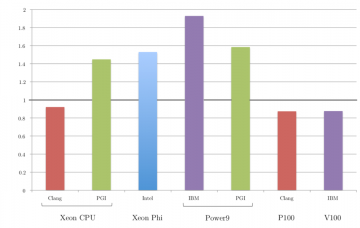
To evaluate the effectiveness of CCAMP’s OpenACC to OpenMP 4.X+ baseline translation pass, we evaluated the hand-coded OpenMP 4.X+ applications in the SPEC Accel benchmark suite without applying any…

High-level programming models are a necessity on future high-performance systems. However, with the diversity of accelerators and hardware vendors, performance portability of applications across the…
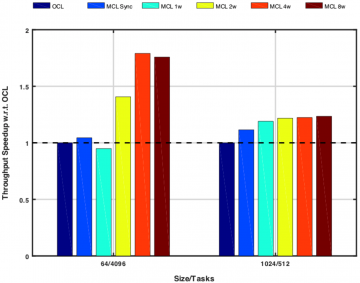
We analyze the overhead introduced by MCL over OpenCL when using similar hardware resources. The goal of this test is to evaluate MCL scheduling overhead, the parallelism exploited by the MCL workers…
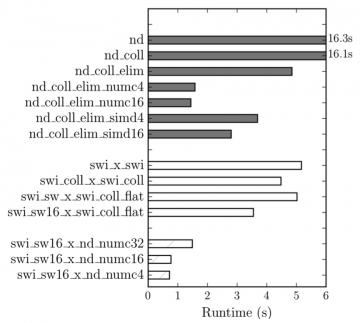
This work examined the directive-based high-level FPGA programming approach implemented in the OpenARC compiler. The experimental results show that multi-threaded and single-threaded kernels can…
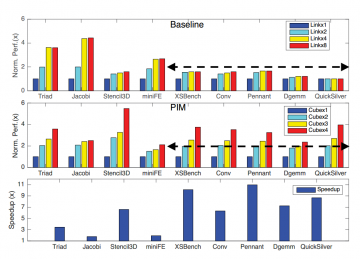
Scaling off-chip bandwidth is challenging due to fundamental limitations such as fixed pin count and plateauing signaling rates. Recently, vendors have turned to 2.5D and 3D stacking to closely…
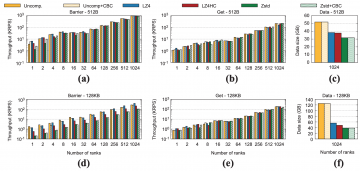
Recently, persistent data structures, like key-value stores (KVSs), which are stored in an HPC system's nonvolatile memory, provide an attractive solution for a number of emerging challenges like…
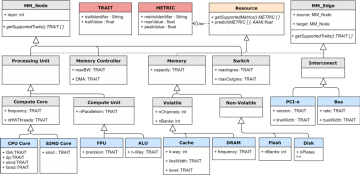
The slowdown of Moore’s law has caused an escalation in architectural diversity over the last decade, and agile development of domain-specific heterogeneous chips is becoming a high priority. However…

This paper describes how the OpenACC data model is implemented in current OpenACC compilers, ranging from research compilers (OpenUH and OpenARC) to a commercial compiler (the PGI OpenACC compiler).…
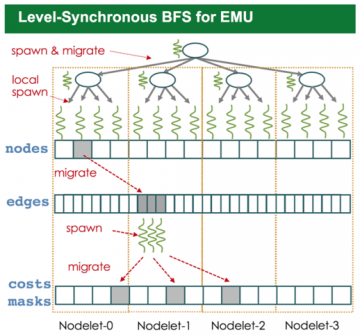
EMU is a novel architecture that provides scalable access to a com- mon partitioned global address space (PGAS) through a simple programming interface. The hardware is hierarchically organized as…
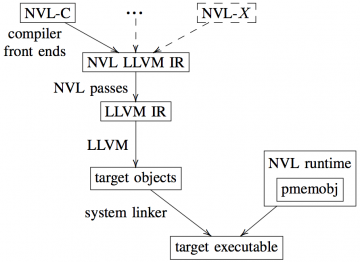
Substantial advances in nonvolatile memory (NVM) technologies have motivated widespread integration of NVM into mobile, enterprise, and HPC systems. Recently, considerable research has focused…
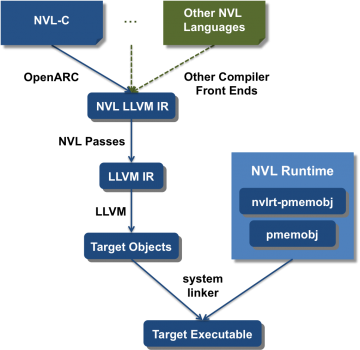
Computer architecture experts expect that NVM hierarchies will play a more significant role in future systems including mobile, enterprise, and HPC architectures. With this expectation in mind, we…
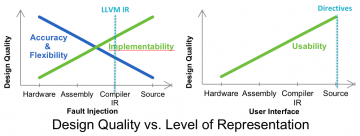
The frequency of hardware errors in HPC systems continues to grow as system designs evolve toward exascale. Tolerating these errors efficiently and effectively will require software-based resilience…

Heterogeneous computing with accelerators is growing in importance in high performance computing (HPC), deep learning (DL), and other areas. Recently, application datasets have expanded beyond the…
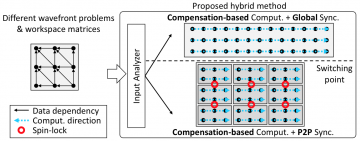
Wavefront loops are widely used in many scientific applications, e.g., partial differential equation (PDE) solvers and sequence alignment tools. However, due to the data dependencies in wavefront…