Achievement
Developed and implemented shrink and substitute approaches to recover from process failures in distributed high-performance computing (HPC) applications. Proposed approaches provide the ability to continue application execution in the presence of failures without the need to discard progress using in-situ reconfiguration, spare processes (if available) and in-memory checkpoints. Demonstrated and compared the efficacy of proposed approaches through implementation in a linear solver application.
Significance and Impact
Demonstrated design tradeoffs and complexities involved in the realization of shrink and substitute recovery approaches for usability in the design of resilient HPC applications.
Research Details
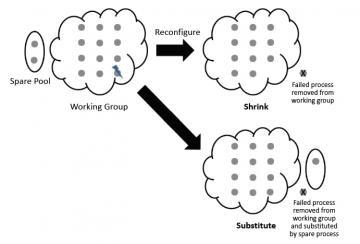
- Demonstrated two distinct approaches to recover from process failures: in one case, the application is resumed using surviving processes only and in the other case, the application is resumed using design-time allocated spare and surviving processes.
- Developed application-driven in-memory checkpoint and state recovery compatible to both shrink and substitute approaches. Shrink approach requires workload rebalancing and substitute approach requires distribution of application state to spare processes.
- Evaluated the performance overheads for in-memory checkpoint and recovery operations at large-scale in the presence of multiple independent processes failures.
Overview
Analyses of large-scale HPC systems has demonstrated the need to implement process failure resilience in long-running applications, which are susceptible to multiple failures during their execution. The failures hinder scientific productivity and can result in significant wastage of resources, since the failure of even one process in a parallel application based on the message-passing programming model results in a fatal application crash. This work explores the utility of User Level Failure Mitigation (ULFM) proposal in the Message Passing Interface (MPI) standard, which provides the ability to detect process failures, isolate failed processes, and reconfigure MPI applications to resume normal operation without the need to reallocate resources in the HPC system. It does not however provide the ability to recover application state and therefore use of in-memory checkpoints, with the option of whether to include spare processes to replace failed processes (substitute approach) or continue execution with surviving processes (shrink approach) is investigated in this work. Replacement of failed processes using spare processes avoids the requirement of dynamic workload rebalancing when continuing execution with surviving processes only, besides some applications can not tolerate the loss of processes due to problem decomposition restrictions. Results assessing overall performance impact of employing substitute and shrink approaches in a linear solver application demonstrate high overheads associated with mapping of spare processes and the potential of surviving processes at large-scale to handle workload of lost processes. The selection of recovery approach depends on application and system characteristics, such as the overheads associated with workload rebalancing and communication disruption due to inclusion of spare processes, availability of spare resources, and code malleability.
Last Updated: May 28, 2020 - 4:04 pm