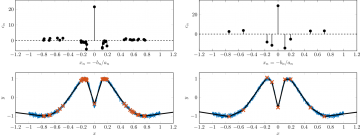
Comparison of solutions to the standard convex problem (left) and of the proposed non-convex penalized problem (right) with 5000 uniformly distributed noisy samples of a one-dimensional target function.
Top: Distribution of neurons.
Bottom: Noisy data (blue), optimal network (black), and knot points of the corresponding linear spline (orange).
Achievement
An improved method for training artificial neural networks based on a new nonconvex regularization approach has been developed. This method is based on integral representations and enjoys favorable theoretical properties similar to convex neural networks (such as theoretically guaranteed dimension independent approximation) and is able to drastically improve the number of neurons that are required for reliable approximation.
Significance and Impact
The main challenge in neural network training is reliably finding a good network that is able to fit the data without excessive overparametrization and associated issues: overfitting, increased training cost, etc. The proposed method successfully overcomes this challenge based on a new optimization formulation with a corresponding adaptive architecture choice and training procedure.
This work also produces the first results that establish various desirable properties of the artificial neural networks obtained in this way. Additionally, the theoretical findings potentially have a much larger range of applications in other areas of signal processing and machine learning.
Research Details
- We investigate shallow neural networks with the ReLU activation function.
- Using the theory of integral representations we reformulate the problem of training and architecture choice as an optimization problem in the space of neural network measures.
- We propose a new nonconvex regularizer of appropriate structure in order to improve upon the sparsity promoting power of convex methods.
- To obtain approximation guarantees, the theory of integral neural networks is deployed and new mathematical results are derived that rigorously establish the improvements over the existing convex methods.
- The optimization problem underlying the training and architecture choice approach is solved using an algorithmic method that leads to improved networks in shorter computational time compared to the convex regularizer.
Overview
Training methods for artificial neural networks often rely on over-parameterization and random initialization in order to avoid spurious local minima of the loss function that fail to fit the data properly. To sidestep this, one can employ convex neural networks, which combine a convex interpretation of the loss term, sparsity promoting penalization of the outer weights, and greedy neuron insertion. Here, the training procedure can be understood as solving a sparse optimization problem on a space of measures. However, the canonical l1 penalty does not achieve a sufficient reduction in the number of neurons in a shallow network in the presence of large amounts of data, as observed in practice, and supported by theory.
As a remedy, we propose a nonconvex penalization method that maintains the aforementioned advantages of the convex approach. We investigate the analytic aspects of the method in the context of neural network integral representations and prove attainability of minimizers, together with a finite support property and approximation guarantees. Additionally, we describe how to numerically solve the minimization problem with an adaptive algorithm combining local gradient-based training, and adaptive node insertion and extraction.
Last Updated: January 14, 2021 - 7:30 pm