Achievement
A multidisciplinary team of researchers from Oak Ridge National Laboratory (ORNL), Pacific Northwest National Laboratory (PNNL), and University of Rome Tor Vergata developed a programming system for heterogeneous computing, called Minos Computing Library (MCL). MCL consists of system software, programming model, and programming model runtime that facilitate programming extremely heterogeneous systems. MCL supports the execution of several multi-threaded applications within the same compute node, performs asynchronous execution of application tasks, efficiently balances computation across hardware resources, and provides performance portability. We show that code developed on a personal desktop automatically scales up to fully utilize powerful workstations with 8 GPUs and down to power-efficient embedded systems. MCL provides up to 17.5x speedup over OpenCL on NVIDIA DGX-1 systems and up to 1.88x speedup on single-GPU systems. In multi-application workloads, MCL’s dynamic resource allocation provides up to 2.43x performance improvement over manual, static resources allocation.
Significance and Impact
Hardware specialization has become the silver bullet to achieve efficient high performance, from Systems-on-Chip systems, where hardware specialization can be “extreme”, to large-scale HPC systems. As the complexity of the systems increases, so does the complexity of programming such architectures in a portable way. To address this issue, we introduce the Minos Computing Library (MCL), a novel runtime system aimed at providing a new level of capability for efficient parallel programming of extremely heterogeneous systems. MCL increases performance portability by transparently scaling applications to systems that feature heterogeneous resources and by enabling programmers to develop code on personal desktop computer and execute on large workstations or HPC compute nodes.
Research Details
- Describe MCL’s design goals and implementation, highlighting the asynchronous programming model, the scheduling framework, and the programming abstraction.
- Demonstrate performance and scalability across multiple platforms, including an NVIDIA DGX-1 workstation and an ARM/GPU embedded system. We show up to 17x performance improvement on the DGX-1 systems and up to 1.8x on a single-GPU compute node compared to OpenCL.
- Show that MCL can fully utilize the hardware resources in the system and provide automatic load balancing.
Citation and DOI: Roberto Gioiosa, Burcu Ozcelik Mutlu, Seyong Lee, Jeffrey S. Vetter, Giulio Picierro, and Marco Cesati. The Minos Computing Library: efficient parallel programming for extremely heterogeneous systems, Proceedings of the 13th Annual Workshop on General Purpose Processing Using Graphics Processing Unit (GPGPU20), 2020; DOI: 10.1145/3366428.3380770
Overview
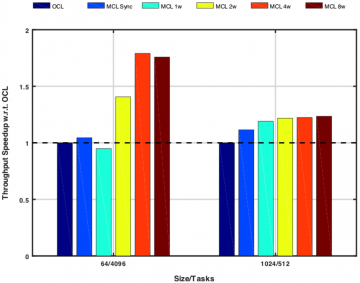
We analyze the overhead introduced by MCL over OpenCL when using similar hardware resources. The goal of this test is to evaluate MCL scheduling overhead, the parallelism exploited by the MCL workers, and the benefits of asynchronous execution. We conduct these tests on the GPU compute node platform, as this system only features one high-performance GPU, thus both OpenCL and MCL will use the same hardware resources.
This figure shows MCL performance with respect to OpenCL (first bar) in terms of throughput (tasks executed/s). In order to highlight runtime overhead we perform tests with small and medium tasks. Runtime overhead is relatively higher with small computational tasks where the amount of computation is not enough to amortize the cost of moving input data to the device, setup the kernel execution, and move output data back to main memory. In this case, MCL performs better than OpenCL by amortizing the overheads using implicit parallelism. For larger tasks, there is enough computation to amortize the cost of data movement. Although, the importance of overlapping data movement and computation is lower, MCL performance matches OpenCL, which indicates that the runtime overhead introduces is relatively small.
Last Updated: January 14, 2021 - 7:36 pm