Achievement
We propose a compensation-based, hybrid method for efficient wavefront loop execution on GPUs, which considers both locality and parallelism for different situations.
Significance and Impact
Many DOE (or related) applications based on PDE solvers can benefits from the proposed work by efficiently parallelizing their wavefront loops (loops with loop-carried dependencies) on heterogeneous architectures.
Research Details
- Design and implement a highly efficient compensation-based parallelism on GPUs.
- Prove under which circumstances that the proposed compensation-based method does not affect the correctness of results.
- Demonstrate that our method can achieve significant improvements for four real-world applications over the state-of-the-art research, when tested on the NVIDIA K80 and P100 GPUs.
Overview
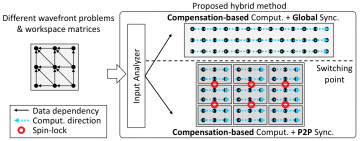
Wavefront loops are widely used in many scientific applications, e.g., partial differential equation (PDE) solvers and sequence alignment tools. However, due to the data dependencies in wavefront loops, it is challenging to fully utilize the abundant compute units of GPUs and to reuse data through their memory hierarchy. Existing solutions can only optimize for these factors to a limited extent. For example, tiling-based methods optimize memory access but may result in load imbalance; while compensation-based methods, which change the original order of computation to expose more parallelism and then compensate for it, suffer from both global synchronization overhead and limited generality.
In this paper, we first prove under which circumstances that breaking data dependencies and properly changing the sequence of computation operators in our compensation-based method does not affect the correctness of results. Based on this analysis, we design a highly efficient compensation-based parallelism on GPUs. Our method provides weighted scan-based GPU kernels to optimize the computation and combines with the tiling method to optimize memory access and synchronization. The performance results on the NVIDIA K80 and P100 GPU platforms demonstrate that our method can achieve significant improvements for four types of real-world application kernels over the state-of-the-art research.
Last Updated: May 28, 2020 - 4:02 pm