Achievement
We compare a suite of memory access schemes for the lattice Boltzmann method on GPUs via empirical testing and performance modelling and find that our recommended addressing modifications lead to better performance than state-of-the-art practices.
Significance and Impact
We present the first near-optimal strong results for LBM with arterial geometries run on GPUs, and we also demonstrate that the proposed recommendations remain valid for large scale, many device simulations, leading to an increased computational speed and average memory reductions.
Research Details
- Examine the computational cost of different data storage strategies for solving LBM on complex geometries with GPUs.
- Find strong evidence that semi-direct addressing is superior for arterial and porous media geometries, and the CSoA memory layout consistently provides computational acceleration with minimal coding effort and negligible memory increase.
Overview
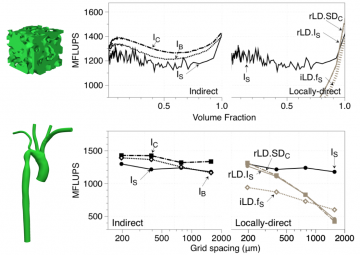
GPU performance of the lattice Boltzmann method (LBM) depends heavily on memory access patterns. When LBM is advanced with GPUs on complex computational domains, geometric data is typically accessed indirectly, and lattice data is typically accessed lexicographically in the Structure of Array (SoA) layout. Although there are a variety of existing access patterns beyond the typical choices, no study has yet examined the relative efficacy between them. Here, we compare a suite of memory access schemes via empirical testing and performance modeling. We find strong evidence that semi-direct addressing is the superior addressing scheme for the majority of cases examined: Semi-direct addressing increases computational speed and often reduces memory consumption. For lattice layout, we find that the Collected Structure of Arrays (CSoA) layout outperforms the SoA layout. When compared to state-of-the-art practices, our recommended addressing modifications lead to performance gains between 10-40% across different complex geometries, fluid volume fractions, and resolutions. The modifications also lead to a decrease in memory consumption by as much as 17%. Having discovered these improvements, we examine a highly resolved arterial geometry on a leadership class system. On this system we present the first near-optimal strong results for LBM with arterial geometries run on GPUs. We also demonstrate that the above recommendations remain valid for large scale, many device simulations, which leads to an increased computational speed and average memory usage reductions. To understand these observations, we employ performance modeling which reveals that semi-direct methods outperform indirect methods due to a reduced number of total loads/stores in memory, and that CSoA outperforms SoA and bundling due to improved caching behavior.
Last Updated: April 16, 2021 - 12:24 pm