Achievement
We propose a deep neural network whose features are captured from both data and compressor characteristics to estimate the compressibility of scientific data and show that adding compressor-specific features can greatly improve the performance of prediction.
Significance and Impact
This paper is among the first to use the deep learning method whose performance is better than the biased estimation and white-box analytical model to understand the data reduction and shows that compressor-specific features play a dominant role in the performance of our model.
Research Details
- Extract features by the data characteristics or the inner mechanisms about compressors
- Compare the performance of compressor-specific features under different samplings
- Compare the performance of deep learning with the sampling and analytical methods
Overview
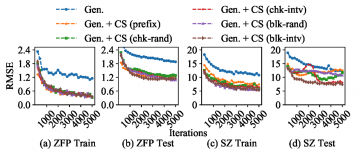
We extract two types of features that impact the overall compression performance: the statistics of data to measure the smoothness of data which is a primary indicator of compressibility and compressor related features to capture the inner mechanisms that a compressor takes to reduce data. In particular, in order to avoid the overhead of compressing complete data, we use different samplings to get the compressor-specific features. And then we train a deep neural network with the extraction features and learn the intrinsic relationships between these features and compression performance. On this basis, we evaluate the impact of compressor-specific features on performance and compare the deep learning model with the sampling and analytical models. It is shown that compressor-specific features can dramatically improve the performance of training and testing for two leading lossy compressors, ZFP and SZ. Meanwhile we can find the deep learning model with compressor-specific features consistently outperforms the analytical model, as well as the sampling-based approach in the case of a biased estimation.
Last Updated: January 14, 2021 - 7:42 pm