Achievement
A team of researchers from Oak Ridge National Laboratory (ORNL) and the University of Oregon investigated the performance of optimizations in ORNL’s OpenACC-to-FPGA framework on a novel FPGA device, an Intel Arria 10. They explored the relationships between optimizations, and the suitability of optimizations for different classes of algorithms.
Significance and Impact
The reconfigurable computing paradigm that uses field programmable gate arrays (FPGAs) has received renewed interest in the high-performance computing field due to FPGAs’ unique combination of performance and energy efficiency. However, difficulties in programming and optimizing FPGAs have prevented them from being widely accepted as general-purpose computing devices. In accelerator-based heterogeneous computing, portability across diverse heterogeneous devices is also an important issue, but the unique architectural features in FPGAs make this difficult to achieve. This work directly impacts these difficulties and issues by investigating and evaluating a high-level directive-based alternative approach for FPGA programming, the OpenACC-to-FPGA framework.
Research Details
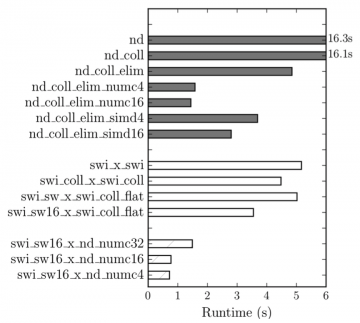
- A categorical organization and summary of optimizations previously developed optimizations were provided.
- Developed optimizations on an array of benchmarks were holistically evaluated using an Arria 10 FPGA.
- The effects of FPGA resource usages and kernel frequencies on runtime performance were explored.
- The necessity of high-level frameworks for efficient FPGA optimization and design exploration and the need to transition to a more automated process were demonstrated.
Overview
This work examined the directive-based high-level FPGA programming approach implemented in the OpenARC compiler. The experimental results show that multi-threaded and single-threaded kernels can perform well on FPGAs, depending on which optimizations can be applied to a specific appli- cation. For example, most applications that allow for advanced single-threaded optimizations outperform their multi-threaded counterparts. In contrast, applications in which these single- threaded optimizations do not apply might perform best using multi-threaded compute unit or SIMD replication.
Last Updated: January 14, 2021 - 7:38 pm