Achievement
Created a multi-user Big Data analytics framework for high-performance computing (HPC) system log data. Used the framework to develop the capability to assess system status, mine event patterns, and study correlations between user applications and events of ORNL’s Titan supercomputer.
Significance and Impact
Understanding the occurrence and relationship of critical events, such as errors and failures, is essential to provide the highest possible performance and reliability in supercomputers. This work offers an easy to use framework to analyze such events and demonstrates its capabilities using ORNL’s Titan supercomputer.
Research Details
- Created a multi-user Big Data analytics framework, called Log processing by Spark and Cassandra-based ANalytics (LogSCAN), that uses Apache Cassandra and Spark in the private cloud of Compute and Data Environment for Science (CADES) at ORNL.
- Analyzed a full year (January 2016 – December 2016) of Titan’s system logs using different Big Data analytics techniques
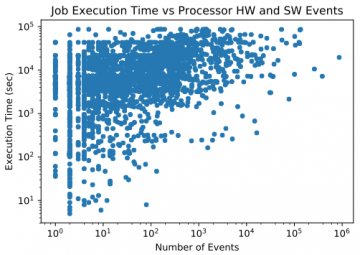
- Performed 3 case studies: Studied the system status of Titan over time, event patterns in Titan’s logs, and correlations between events in Titan’s logs and application run times.
Overview
Reliability, availability and serviceability (RAS) logs of HPC resources, when closely investigated in spatial and temporal dimensions, can provide invaluable information regarding system status, performance, and resource utilization. These data are often generated from multiple logging systems and sensors that cover many components of the system. The analysis of these data for finding persistent temporal and spatial insights faces two main difficulties: the volume of RAS logs makes manual inspection difficult and the unstructured nature and unique properties of log data produced by each subsystem adds another dimension of difficulty in identifying implicit correlation among recorded events. To address these issues, we recently developed a multi-user Big Data analytics framework for HPC log data at ORNL. Our initial accomplishments are three in-progress data analytics projects that leverage this framework to assess system status, mine event patterns, and study correlations between user applications and system events using log data collected from ORNL's Titan supercomputer.
The Log processing by Spark and Cassandra-based ANalytics (LogSCAN) framework is implemented in the private cloud of Compute and Data Environment for Science (CADES) at ORNL. It consists of an Apache Cassandra distributed NoSQL database, an Apache Spark in-memory data processing engine, a separate query processing engine, and a front-end. LogSCAN can serve simultaneous queries from multiple users, who may also require long-lived connections.
Our ongoing work in assessing Titan’s system status incorporates principal component analysis (PCA) and information entropy analysis. PCA is a standard machine learning algorithm and is being used to reduce the dimensionality of collected data while continuing to represent the features in the original data for system status identification. The information entropy analysis creates a numeric indicator of the average amount of non-redundant information in the collected data that can be used to identify changes in system status.
Our ongoing work in mining event patterns uses association rule mining to compute temporal correlations of events recorded in the logs. This allows us to identify potential causal relationships between events. We also applied the FPGrowth algorithm of the Spark library to generate frequent event sets. We further perform text mining using word2vec to produce event patterns whose occurrences are dominant during a period of interest.
Our ongoing work in studying correlations between user applications and system events additionally uses data from the Cray Application Level Placement Scheduler (ALPS). By correlating this data with the logged events, we can identify the impact of events on application job execution times.
Last Updated: May 28, 2020 - 4:05 pm