Citation
Ferrol Aderholdt, Manjunath Gorentla Venkata, and Zachary W. Parchman. SharP Data Constructs: Data Constructs for Data-centric Computing. In Proceedings of the 26th Euromicro International Conference on Parallel, Distributed, and network-based Processing (PDP) 2018, Cambridge, UK, March 21-23, 2018.
Abstract
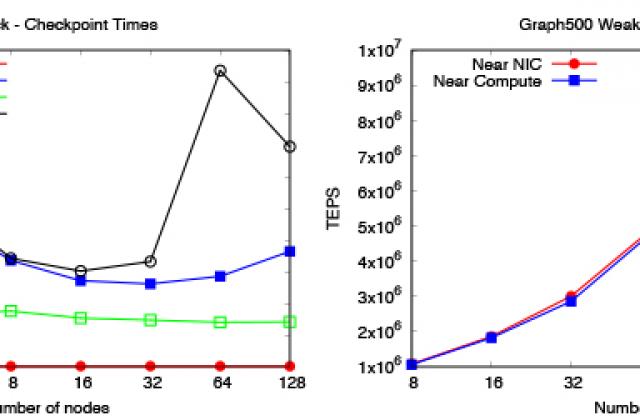
Extreme-scale applications (i.e., Big-Compute) are becoming increasingly data-intensive, i.e., producing and consuming increasingly large amounts of data. The HPC systems traditionally used for these applications are now used for Big-Data applications such as data analytics, social network analysis, machine learning, and genomics. As a consequence of these trends, the system architecture should be flexible and data-centric. This can already be witnessed in the pre-exascale systems with TBs of on-node hierarchical and heterogeneous memories, PBs of system memory, low-latency, high-throughput networks, and many threaded cores. As such, the pre-exascale systems suit the needs of both Big-Compute and Big-Data applications. Though the system architecture is flexible enough to support both Big-Compute and Big-Data, we argue there is a software gap. Particularly, we need data-centric abstractions to leverage the full potential of the system, i.e., there is a need for native support for data resilience, the ability to express data locality and affinity, mechanisms to reduce data movement, the ability to share data, and abstractions to express User’s data usage and data access patterns. In this paper, we (i) show the need for taking a holistic approach towards data-centric abstractions, (ii) show how these approaches were realized in the SHARed data-structure centric Programming abstraction (SharP) library, a data-structure centric programming abstraction, and (iii) apply these approaches to a variety of applications that demonstrate its usefulness. Particularly, we apply these approaches to QMCPack and the Graph500 benchmark and demonstrate the advantages of this approach on extreme-scale systems.
Read Publication
Last Updated: May 28, 2020 - 4:04 pm