Achievement
Developed an understanding of network interconnect errors and network congestion in ORNL’s Titan supercomputer. The results show that: (1) the magnitude of errors is very high and distributed unevenly across different types of links with-in and across cabinets, (2) some errors have a strong spatial correlation, while others show counter-intuitive patterns, and (3) congestion events are highly frequent, bursty and not homogeneously distributed across blades.
Significance and Impact
Understanding errors and performance degradation in supercomputer network interconnects is essential to provide the highest possible performance and reliability in supercomputers. This work provides new insights for ORNL’s Titan system that can be applied to improve the operation of Titan and other current and future supercomputers through changes in network usage and design.
Research Details
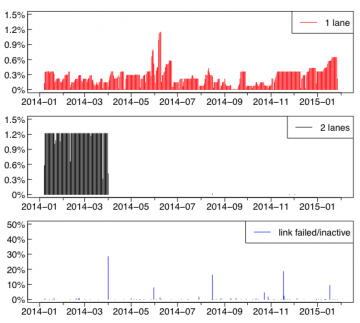
- Analyzed a full year (January 2015 – January 2016) of Titan’s system logs, specifically focusing on logs from the xtnetwatch and xtnlrd deamons that collect network error and congestion information.
- Characterized the temporal and spatial locality of network interconnect errors, including for each individual error type.
- Characterized the temporal and spatial locality of network congestion events, including for the top 5 congestion-causing applications.
Overview
Today's High Performance Computing (HPC) systems are able to deliver performance in order of Petaflops due to fast computing devices, interconnect, and back-end storage systems. HPC systems contain tens of thousands of processors which require an advanced interconnect network to minimize system latency and maximize throughput and scalability for tightly-coupled parallel scientific applications. Performance of these interconnects depends on network topology, routing, flow-control algorithm, resilience mechanism, congestion reaction mechanism, and communication pattern of applications. In particular, the interconnect resilience mechanism and congestion resolution mechanism have a major impact on the overall interconnect and application performance, especially for scientific applications where multiple processes running on different compute nodes rely on fast network messages to communicate and synchronize frequently.
Unfortunately, the community lacks state-of-practice experience reports that detail how different interconnect errors and congestion events occur on a large-scale HPC system. Therefore, in this paper, we study the interconnect resilience and congestion on the Titan supercomputer, the fastest open-science supercomputer in the world. Daemon services on this system collected useful interconnect resilience and congestion events on the Titan supercomputer for more than a year. We gathered, processed, and analyzed this data to develop a thorough understanding of interconnect faults, errors, and congestion events. Our analysis can be categorized along following three dimensions:
- What are major interconnect fault and errors?
- What are the key characteristics of different interconnect errors and network congestion events?
- What is the interaction between interconnect errors, network congestion, and application characteristics?
This study exploits various daemons, such as netwatch and nlrd, used in collecting and logging interconnect related events. However, analysis of this data presents several fold challenges. First, the collected data has a lot of noise that we need to filter carefully for more accurate analysis. Second, the logs patterns differ for the same type of events across different logging mechanisms. We need to develop unified format types for different events. Finally, as data was distributed across several nodes and storage location, it requires performing multi-source analytics to ensure consistency and accuracy.
Results summary:
- The magnitude of interconnect errors is very high and is distributed unevenly across different types of links with-in and across cabinets.
- Some interconnect errors have a strong spatial correlation among them, while some other errors show counter-intuitive patterns.
- Network congestion events are highly frequent and bursty. Network congestion events are not homogeneously distributed across blades.
- Applications and users causing network congestion and high communication intensity in the supercomputer have interesting job characteristics.
Last Updated: May 28, 2020 - 4:04 pm