Achievement
Paper titled "Balanced k-Means Clustering on an Adiabatic Quantum Computer" accepted for publication at the Springer Quantum Information Processing journal.
Significance and Impact
Training machine learning models on classical computers that use CPUs and GPUs is a time consuming process. It will be infeasible to continue the current practices for training machine learning models beyond the Moore's law. Therefore, we must leverage non-conventional computing platforms such as quantum computing to train machine learning models beyond the Moore's law. To this extent, adiabatic quantum computers are a promising platform for efficiently solving challenging optimization problems. Therefore, many are interested in using these computers to train computationally expensive machine learning models as well. If successful in training machine learning models faster, with high accuracy and with high reliability, quantum computers would pave the way for scientific discovery through effective data analysis beyond the Moore's law.
Research Details
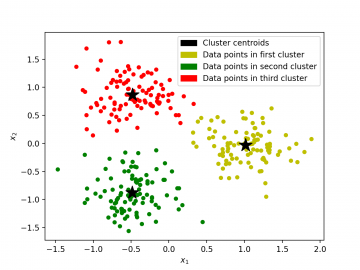
In this paper, we present a quantum approach to solving the balanced k-means clustering training problem on the D-Wave 2000Q adiabatic quantum computer. Specifically, we formulate the training problem of balanced k-means clustering as a quadratic unconstrained binary optimization (QUBO) problem. Unlike existing classical algorithms, our QUBO formulation targets the global solution to the balanced k-means model. We test our approach on a number of small problems and observe that despite the theoretical benefits of the QUBO formulation, the clustering solution obtained by a modern quantum computer is comparable to the solution obtained by classical clustering algorithms. The solutions provided by the quantum computer also exhibit some promising characteristics. We also perform a scalability study to estimate the run time of our approach on large problems, that could be solved using future quantum hardware. As a final proof of concept, we used the quantum approach to cluster random subsets of the Iris benchmark data set.
Last Updated: August 31, 2021 - 11:41 am