Achievement
In collaboration with LBNL and ANL staff, we developed a new model of metadata for supporting efficient movement of scientific data between two parallel codes that are of different size. With the release of SENSEI 3.2, ADIOS technology led by an ORNL team has been incorporated as a reference implementation for this new capability.
Significance and Impact
This work enables right-sizing of resources used for analysis and visualization components, so that resources are not wasted on the producer or consumer side.
Research Details
- Mapping initial ADIOS 1.X schema into the new ADIOS 2.X API
- Used the many available ADIOS engines to test different strategies for in transit communication
- Leveraged ADIOS 2.5 capabilities to support AMR science codes.
Overview
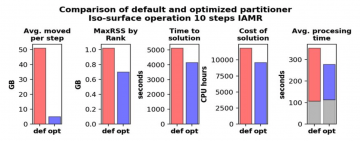
In an in transit setting, a parallel data producer, such as a numerical simulation, runs on one set of ranks M, while a data consumer, such as a parallel visualization application, runs on a different set of ranks N. One of the central challenges in this in transit setting is to determine the mapping of data from the set of M producer ranks to the set of N consumer ranks. This is a challenging problem for several reasons, such as the producer and consumer codes potentially having different scaling characteristics and different data models. The resulting mapping from M to N ranks can have a significant impact on aggregate application performance. In this work, we present an approach for performing this M-to-N mapping in a way that has broad applicability across a diversity of data producer and consumer applications. We evaluate its design and performance with a study that runs at high concurrency on a modern HPC platform. By leveraging design characteristics, which facilitate an “intelligent” mapping from M-to-N, we observe significant performance gains are possible in terms of several different metrics, including time-to-solution and amount of data moved.
Last Updated: January 14, 2021 - 7:43 pm