Achievement
We designed a new algorithm to improve the strong scalability of right-looking sparse LU factorization on distributed memory systems. Our 3D algorithm for sparse LU uses a three-dimensional MPI process grid, exploits elimination tree parallelism, and trades off increased memory for reduced per-process communication.
We also analyze the asymptotic improvements for planar graphs (e.g., those arising from 2D grid or mesh discretizations) and certain non-planar graphs (specifically for 3D grids and meshes). Our algorithm provably reduces the asymptotic communication volume and latency for planar-graphs. For non-planar cases, our algorithm can reduce the per-process communication and latency volume by a constant factor.
Significance and Impact
The 3D sparse LU factorization algorithm reduces the asymptotic communication complexity for planar sparse matrices and by a constant factor for non-planar sparse matrices.
The 3D sparse LU factorization algorithm improves the strong scaling from 1000 cores to 32,000 cores on problems of interest.
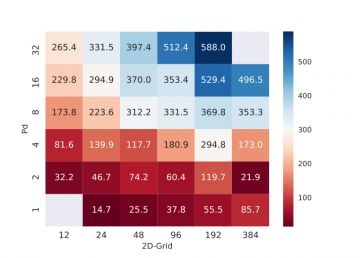
Our new 3D code achieves empirical speedups up to 27× for planar graphs and up to 3.3× for non-planar graphs over the baseline 2D SuperLU_DIST when run on 24,000 cores of a Cray XC30. We extend the 3D algorithm for heterogeneous architectures by adding the Highly Asynchronous Lazy Offload (Halo) algorithm for co-processor offload. On 4096 nodes of a Cray XK7 with 32,768 CPU cores and 4096 Nvidia K20x GPUs, the 3D algorithm achieves empirical speedups up to 24× for planar graphs and 3.5× for non-planar graphs over the baseline 2D SuperLU_DIST with co-processor acceleration.
All of it serves to better utilization of supercomputing resources and enables faster completion of many scientific applications.
Research Details
We wish to improve the strong scalability of sparse direct solvers, which given a large and sparse coefficient matrix A solve the system of linear equations Ax = b by Gaussian elimination or sparse LU factorization. In the strong scaling regime, the communication costs eventually become relatively more expensive. Therefore, we have redesigned the sparse LU factorization algorithms to reduce communication by using a three-dimensional MPI process grid, exploiting elimination tree parallelism, and trading off increased memory for reduced per-process communication. We show that all these techniques when combined together, reduces the asymptotic communication costs, and therefore, are significantly more scalable than the previous state-of-the-art 2D algorithm for sparse LU factorization.
We implement this scheme on top of SuperLU_DIST, using a hybrid MPI+OpenMP programming model as well as for hybrid architecture consisting of both multicore CPU and co-processors such as GPU or Xeon-Phi. We augment the 3D algorithm with the Halo algorithm ([1]) for offloading the compute-intensive Schur-complement update computations to the co-processor. The Halo algorithm, like the 3D factorization algorithm, uses data replication to reduce the communication between host multicore and the co-processor.
Publication
Sao, Piyush, Ramakrishnan Kannan, Xiaoye Sherry Li, and Richard Vuduc. "A communication-avoiding 3D sparse triangular solver." In Proceedings of the ACM International Conference on Supercomputing, pp. 127-137. ACM, 2019 https://www.osti.gov/biblio/1559632, https://doi.org/10.1016/j.jpdc.2019.03.004
Overview
We propose a new algorithm to improve the strong scalability of right-looking sparse LU factorization on distributed memory systems. Our 3D algorithm for sparse LU uses a three-dimensional MPI process grid, exploits elimination tree parallelism, and trades off increased memory for reduced per-process communication. We also analyze the asymptotic improvements for planar graphs (e.g., those arising from 2D grid or mesh discretizations) and certain non-planar graphs (specifically for 3D grids and meshes). For a planar graph with $n$ vertices, our algorithm reduces communication volume asymptotically in $n$ by a factor of OO (√log n)(log n) and latency by a factor of OO (log n)(log n). For nonplanar cases, our algorithm can reduce the per-process communication volume by 3× and latency by OO (n13)(n13) times. In all cases, the memory needed to achieve these gains is a constant factor. We implemented our algorithm by extending the 2D data structure used in SuperLU_DIST. Our new 3D code achieves empirical speedups up to 27× for planar graphs and up to 3.3× for non-planar graphs over the baseline 2D SuperLU_DIST when run on 24,000 cores of a Cray XC30. We extend the 3D algorithm for heterogeneous architectures by adding the Highly Asynchronous Lazy Offload (Halo) algorithm for co-processor offload. On 4096 nodes of a Cray XK7 with 32,768 CPU cores and 4096 Nvidia K20x GPUs, the 3D algorithm achieves empirical speedups up to 24× for planar graphs and 3.5× for non-planar graphs over the baseline 2D SuperLU_DIST with co-processor acceleration.
Last Updated: January 15, 2021 - 11:45 am