Achievement
We investigated the suitability of offloading kernels from HPC scientific applications onto a processing-in-memory (PIM) subsystem. Our simulation results show that such an architecture can potentially result in improved scaling for low to medium arithmetic-intensive applications. We also quantified the impact of data locality to provide design insights for PIM subsystems.
Significance and Impact
Recent advances in 3D stacking technology have revived interest in PIM. Prior research has explored suitability of PIM architectures for data analytics workloads and for specific stacked memory devices. In contrast, we investigate design tradeoffs to enable offloading kernels from scientific applications onto a PIM subsystem. We foresee memory-intensive kernels being offloaded to a PIM subsystem similar to how compute-intensive kernels are offloaded to GPU accelerators today.
Research Details
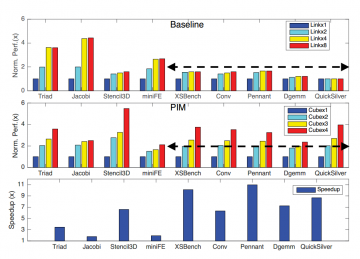
We used the ZSim simulator to model host and PIM cores and interfaced it with the NVMain memory simulator to model 3D stacked memories. Given the area constraints and the scientific domain, our design used four PIM cores per cube, with each core having a floating point unit (FPU) and a small 32KB data and instruction caches, and with four cubes fully interconnected to for the PIM subsystem. We configured a baseline multicore systems with 16 out-of-order cores, each core with a 32KB L1 and 256 KB L2 cache, and with a shared 20 MB L3 cache. Our evaluation used a set of scientific applications from MachSuite, PolyBench, and the ECP proxy application catalog. As shown in the figure, applications achieved 1.76x to 10.97x speedup compared to the baseline. The PIM system proportionally increases bandwidth and compute capability together when adding a memory stack. On the baseline system, applications with higher arithmetic intensity saturate scaling after the bandwidth is doubled, while on the PIM system, these applications continue scaling.
We also evaluated the impacts of translation lookaside buffer (TLB) locality, of remote cube access, and of the PIM's reduced cache hierarchy. We found that TLB size was not a priority optimization for the evaluated applications. Applications that are memory-intensive with lower arithmetic intensities lost significant performance due to remote cube accesses, which could potentially be reduced using a shared L2 cache per cube but at a cost of increased area. Applications with high locality in L2 and L3 caches on the baseline system experienced dramatically increased memory traffic when moving to the PIM system, while other applications had same or moderately increased traffic.
Overview
Scaling off-chip bandwidth is challenging due to fundamental limitations such as fixed pin count and plateauing signaling rates. Recently, vendors have turned to 2.5D and 3D stacking to closely integrate system components. These stacking technologies can integrate a logic layer under multiple memory dies, enabling compute capability inside a memory stack. In this research, we investigate the suitability of offloading kernels from scientific applications onto a 3D stacked processing-in-memory (PIM) architecture. We perform extensive simulation experiments to quantify the impact of application locality and to identify design opportunities for software and hardware.
Last Updated: May 28, 2020 - 4:02 pm